A Slipper Classifier using Logistic Regression
Introduction
I had learned some Machine Learning knowledge, and would like to try to apply it on a real-world project. Slippers are commonly used in our daily life. I was thinking if there is a robot who can collect my slippers and put them in the shelf, I would buy it. So I chose slippers as my model training target. Logistic Regression was the training method in this project. The best Performance was: Training accuracy is 57%; Testing Accuracy is 53%.

First Version
This version only has Training Data Set and Testing Data Set. Train Set has 1309 pictures, whereas Test Set has 141 pictures.
Steps
1. Download image from Google
I downloaded slippers images and non-slippers images.
2. Resize them to 64 x 64 pixels

- Encountered a technical error when resizing the file:
- "cannot write mode P as JPEG
- solved by this code:

3. Manually label all the pictures
At that time, I didn't we can do this via python script. So I labeled all of the pictures.
Training data labels:

Testing data labels:

I put the labels in .txt files.
4. Import data into numpy
I learned from this
link to import image to numpy. Check the data vector size:
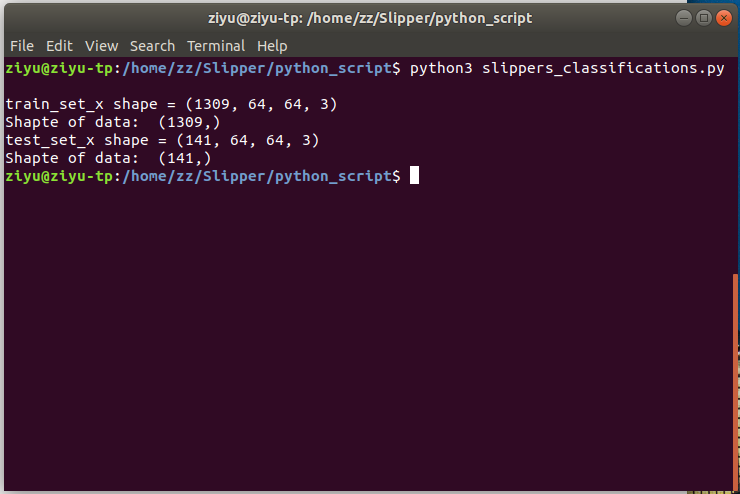
train_set_x shape = (1309, 64, 64, 3) means there are 1309 pictures in my folder, each picture is 64 x 64 pixels and 3 number representing each pixel's RGB value. This shows that the folder is imported to numpy correctly.
5. Developing the model code:
6. Result
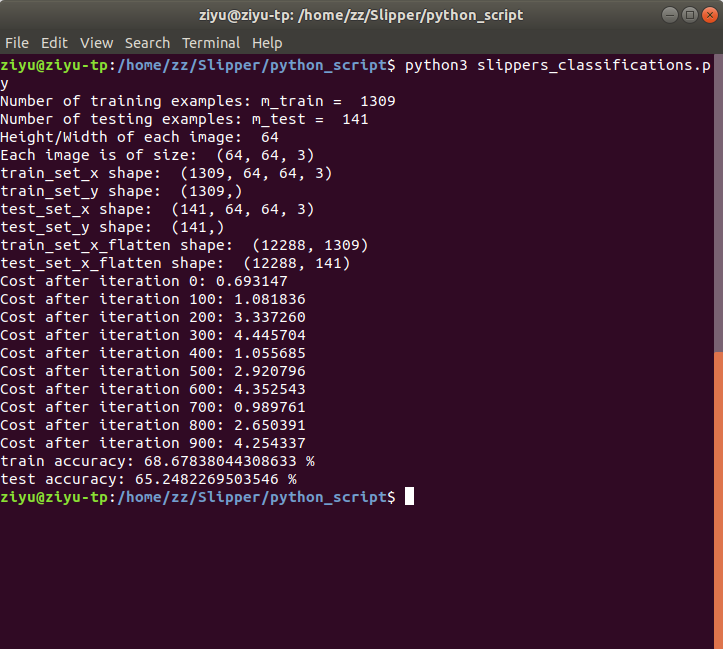
Trained a model that has 68.7% accuracy on Training set and 65.5% accuracy on Testing set.
I changed the iteration number and learning rate with different values, and got some better Training performance but lower testing performance:
I think it is highly possible that the model is over fitting the training set. So I stopped pivot the values and thinking maybe adding more pictures might solve the problem.
Second Version
Data augmentation
My goal was to increase the data set to 10,000 pictures. I couldn't find that much picture, so I decided to use
data augmentation theory to get more pictures. Here is a very good tutorial to show how to use Python and Keras do data augmentation:
link.
I had 624 raw data pictures, my target was to get 5,000 slippers pictures and 5,000 non-slippers.
The data augmentation features I used:
Width_shift_range
Height_shift_range
Rotation_range
Horizontal_flip
Brightness_range
zoom_range
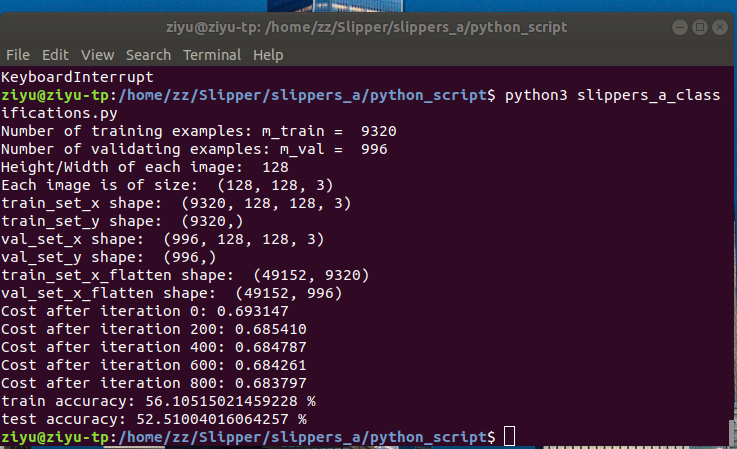
In the end, this version has Training Data Set, Validation Data Set and Test Data Set. Training set has 9320 pictures, Validation set has 996 pictures and Testing set has 1000 pictures.
Result
The Training accuracy is 56%.
The Testing accuracy is 52%.
They are both lower than the model trained with less data. I pivoted the iteration number and learning rate:
1000 0.00001

10000 0.00004

2000 0.00008

2000 0.00015

2000 0.0002

2000 0.004

4000 0.004

10000 0.002

10000 0.0023

According to the result, when iteration time is 2,000 and learning rate is 0.0002 it has the best performance: Training accuracy is 57%; Testing accuracy is 53%. Again, this performance didn't beyond the first version performance. Does it mean more data doesn't always improve the model accuracy?
Others
Please visit GitHub for detailed database and codes: Project Link



No comments:
Post a Comment